.webp)
The algorithms that make quantum computing transformative require millions to trillions of reliable operations. Achieving that reliability requires quantum error correction: bundling noisy physical qubits into protected logical qubits that can sustain long computations.
A key challenge is how many physical qubits the encoding requires, and the answer depends on the capability of the underlying hardware and the error-correcting code. There are multiple families of quantum error-correcting codes, and how efficiently they protect information depends on what the hardware can physically do. Superconducting qubits, for example, are fixed in place on a chip and can only interact with a fixed set of neighbors. This limited connectivity constrains the types of error-correcting codes that can be easily implemented, and most known codes for this architecture are low-rate, requiring many physical qubits to encode a single reliable logical qubit. Scaling to millions of qubits to enable large-scale logical applications is a major engineering challenge that has put these approaches far in the future.
But if the ratio can be dramatically reduced, so can the size of the machine. Fewer physical qubits per logical qubit means a smaller, nearer-term system can do the same work.
Our latest paper, from a research team spanning QuEra (Chen Zhao, Casey Duckering), Harvard (Andi Gu), and MIT (Nishad Maskara, Hengyun Zhou), demonstrates such a reduction. Most approaches today need hundreds to thousands of physical qubits to build one reliable logical qubit. We show it can be done with just over two. Building on a recent theory breakthrough (Kasai, 2026), we show that quantum error-correcting codes with encoding rates above 1/2 could be used in practical settings, and directly verify in simulation that they can achieve error rates as low as one error per trillion steps.
With these ultra-high rates, a system of tens of thousands of physical qubits could deliver the logical qubit counts and low error rates that many proposed algorithms require. This brings useful quantum computing closer.
To be clear about scope: this paper is a quantum memory result. We show that logical information can be stored with extremely low error rates at high encoding efficiency, and further developments will be needed to establish all ingredients for full fault-tolerant computation. But memory is the foundation. If a quantum computer can’t hold information reliably, it can’t compute reliably either. The encoding efficiency demonstrated here directly determines how large that computer needs to be.
Our results show that neutral atoms have a clear path to the Teraquop regime, roughly one error per trillion logical operations. This is the fidelity threshold where quantum computers become capable of running the deep algorithms proposed for molecular simulation, optimization, and cryptanalysis.
Evolving LDPC Codes for Quantum Computing
The idea behind this work has its roots in classical coding theory. Classical LDPC codes have existed for decades, and modern LDPC codes inside 5G, Wi-Fi, and deep-space links operate at very high rates, sometimes as high as 90%, when measuring bits of payload per bit transmitted. These mature systems operate near the Shannon limit: the theoretical maximum information transmission rate. Quantum error correction inherits the same mathematical family, but practical finite-size quantum LDPC (qLDPC) codes have been stuck at rates between 1/10 and 1/100. This means that for every logical qubit, ten to a hundred physical qubits are needed.
Kasai's recent construction showed that rate 1/2 qLDPC codes are mathematically reachable at large block sizes. The open question our collaboration between QuEra, Harvard, and MIT has been exploring in recent months is whether those ultra-high rates are reachable at smaller, practical block sizes, under realistic hardware control assumptions and physical error rates, and whether they can achieve logical error rates that are relevant to large-scale algorithms.
Based on our results, the answer is yes.
Headline Results
- [[n = 1152, k = 580, d ≤ 12]] — encoding 580 logical qubits into 1152 physical qubits, achieving an encoding rate of 0.503, and protecting against up to 5 errors
- [[n = 2304, k = 1156, d ≤ 14]] — encoding 1156 logical qubits into 2304 physical qubits, achieving an encoding rate of 0.502, and protecting against up to 6 errors
- We design these codes to satisfy new structural conditions that enable very efficient atom movement, making them well-suited for neutral-atom platforms
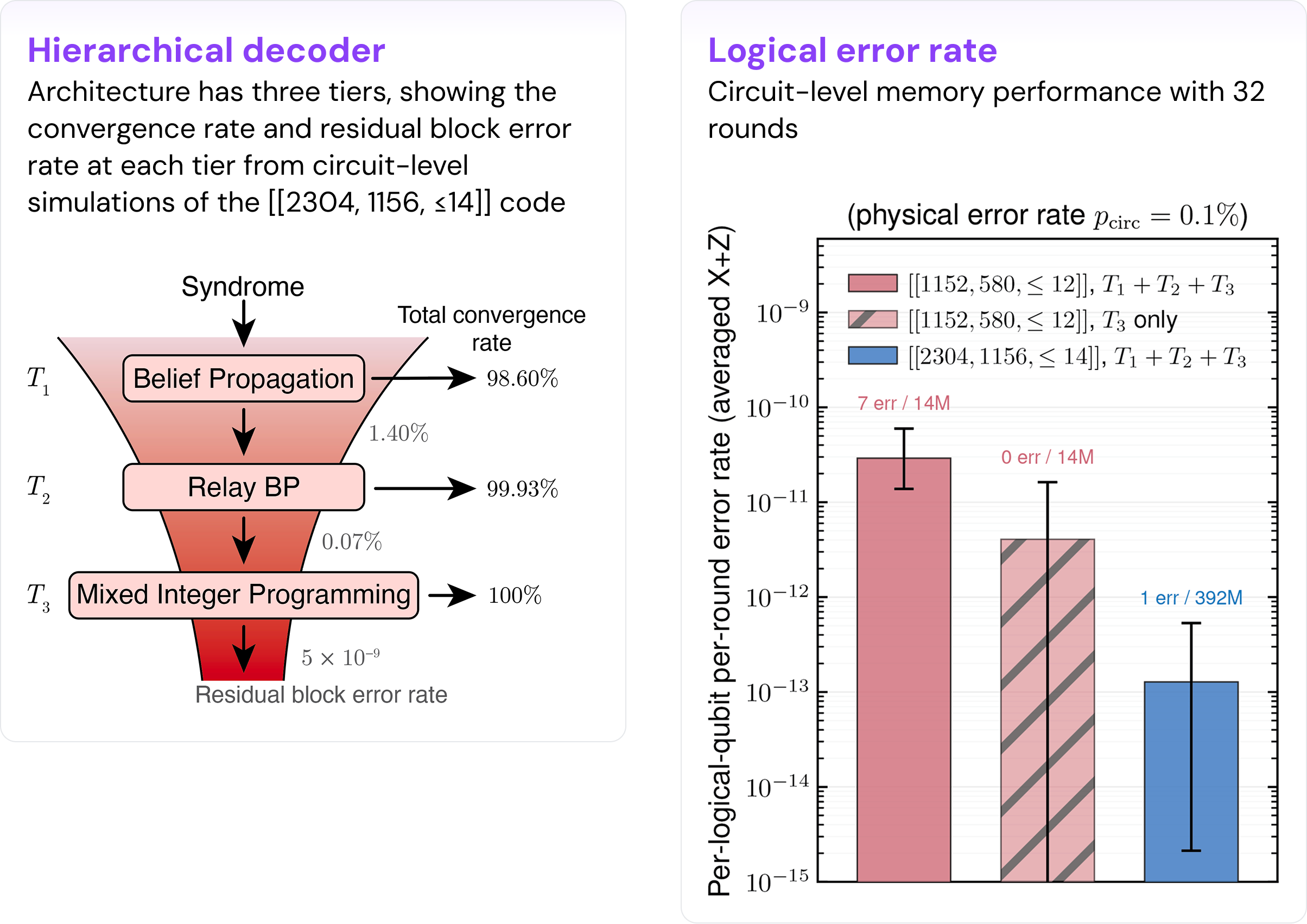
- Per-logical-per-round error rate approaching the Teraquop regime: 1.3⁺³·⁰₋₀.₉ × 10⁻¹³, under a realistic circuit-level noise model and using a new decoder
The rest of this post describes how we co-designed the code and benchmarked its performance, why it is particularly well-suited for neutral atom platforms like QuEra’s, and where the result sits in the rapidly evolving, broader QEC landscape.
Co-Designing the Kasai Family for Neutral-Atom Hardware
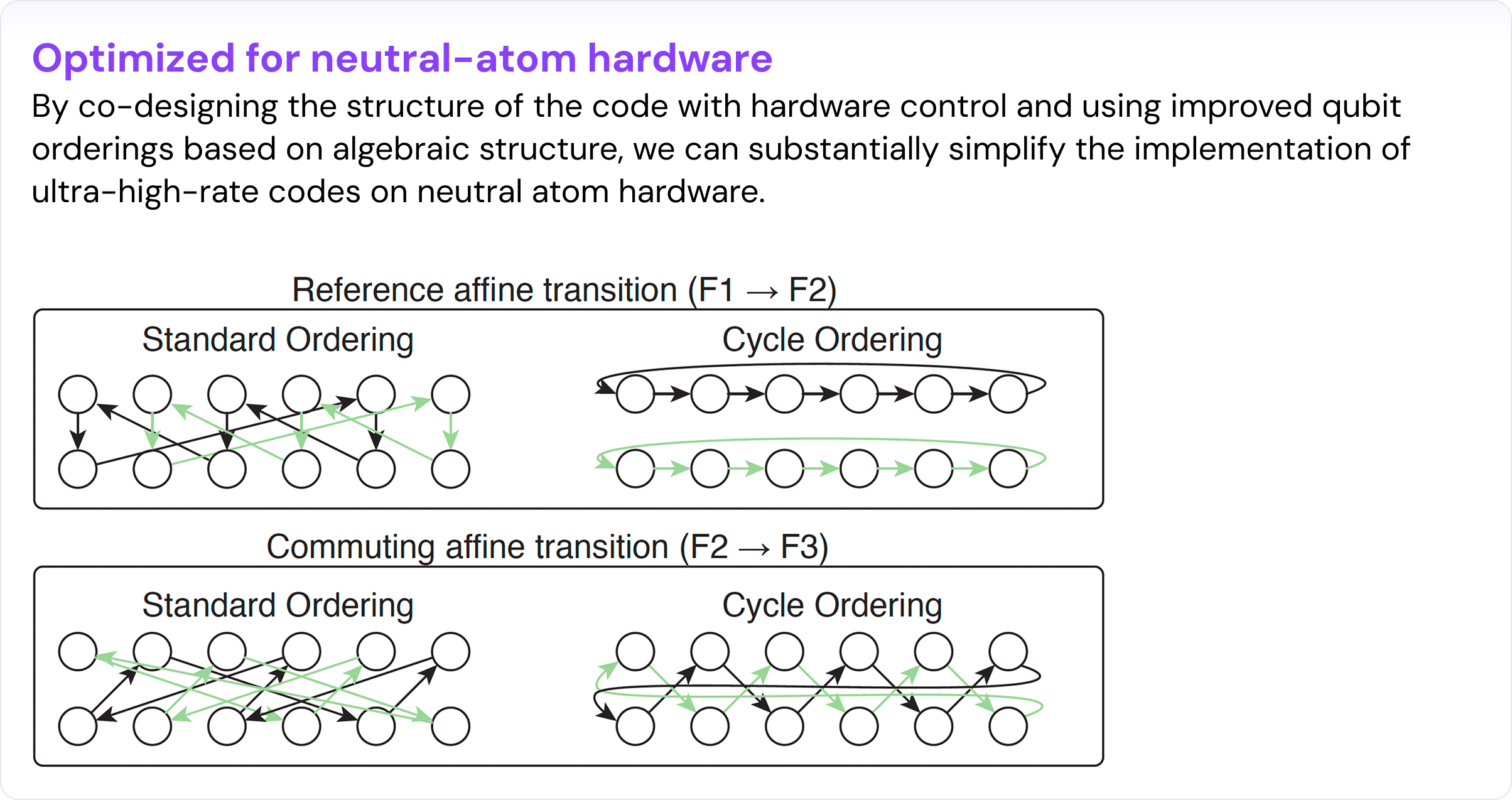
Kasai's construction ([Kasai, 2026]) was the advance that made ultra-high-rate quantum codes more realistic. It introduced affine permutation matrices — maps of the form x → ax + b (mod P) — in place of the circulant permutation matrices that earlier quantum LDPC constructions relied on. Because affine permutations don't mutually commute, the construction escapes previous performance limitations, making rates around 1/2 and large distances achievable.
However, reaching rate 1/2 in theory and reaching it on real hardware are different problems. Our paper bridges that gap through co-design: shaping the code construction around the specific capabilities and constraints of reconfigurable neutral-atom systems.
Reconfigurable neutral-atom systems move atoms using Acousto-Optic Deflectors (AODs) with a row-column product structure. That structure is simultaneously a constraint and a gift: you don't get arbitrary parallel permutations, but you do get massively parallel moves with a well-characterized control model. We adapted the Kasai code family to work well with these design constraints.
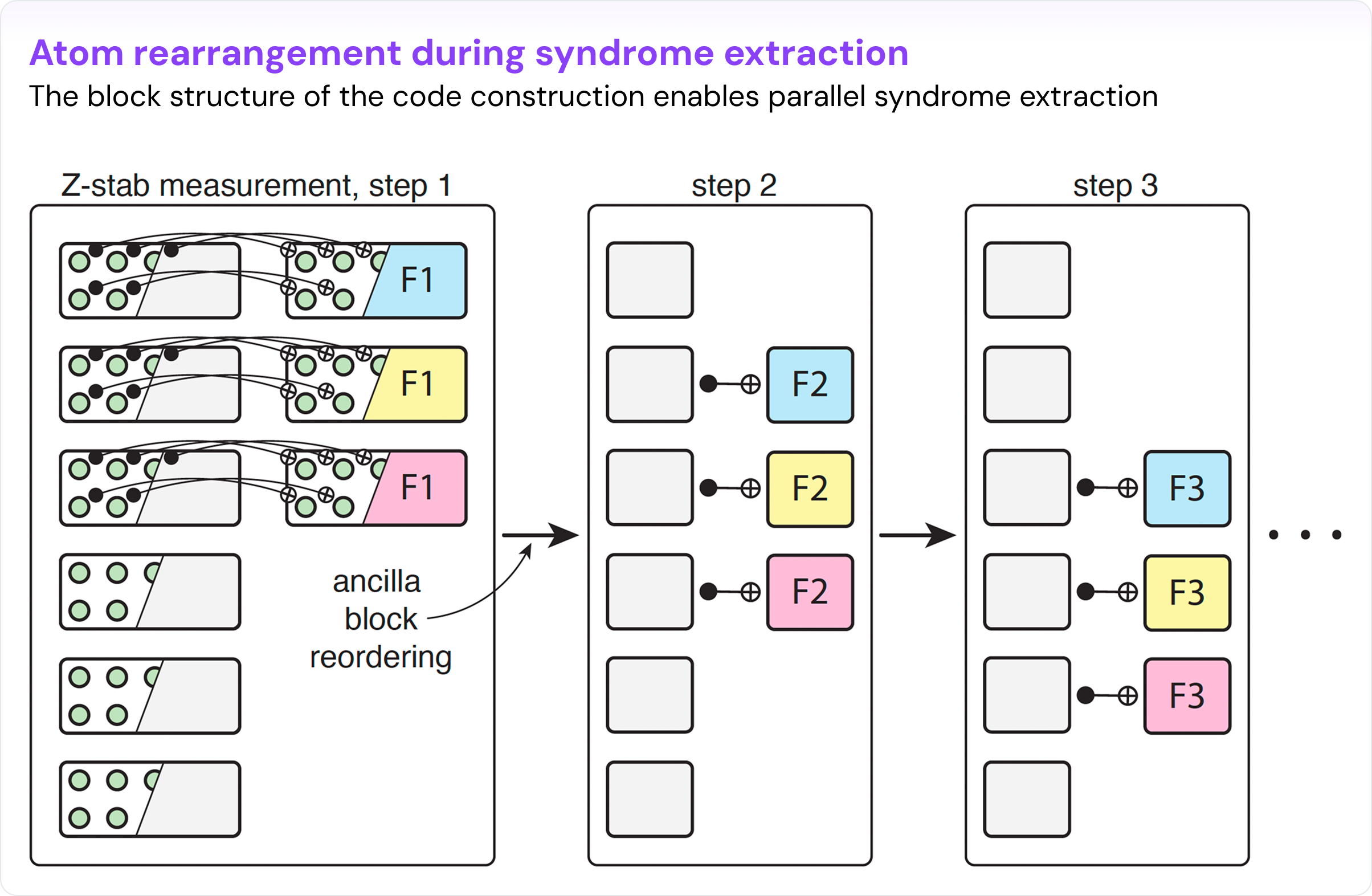
Structural conditions that compile to hardware. The central co-design insight concerns the orbit structure of the transition APMs — the permutations that move ancilla atoms from one syndrome-extraction step to the next. These transition permutations directly control how complex the atom movement is. By choosing a reference APM with large orbits and designing the transition APMs to commute with it, the required motion collapses to simple cyclic shifts within orbits and permutations between them — executable in low AOD depth. For the [[n = 1152, k = 580]] code, each block in the construction factors as 3 × 32. The code is laid out on a 3 × 32 grid, and each syndrome step requires at most one horizontal shift and one vertical shift or swap, making its implementation well-suited for our neutral-atom parallel control tools.
Without this co-designed structure, an arbitrary APM takes O(log n) movement depth — still fairly efficient, and our paper gives a general algorithm for it. But constant depth is what makes the syndrome cycle fast enough to be practical, and achieving it requires designing the code and the hardware execution together.
Smaller, realistic block sizes. The co-design also shaped the code search itself. Kasai's original search emphasized girth-8 instances, while we relax to girth-6, as we find that under moderate physical error rates, we can achieve similar performance for both under BP decoding with post-processing. Relaxing it recovers the search freedom needed to find good instances near n = 1,000 — the block size relevant to the first generation of utility-scale quantum algorithms — while simultaneously satisfying the structural conditions that make hardware compilation efficient.
Validating the Performance of Ultra-High-Rate Codes
An ultra-high-rate code is only as credible as the simulation that validates it. Validating the performance of such error-correcting codes is highly non-trivial. On the one hand, we want to achieve very good accuracy, which demands sophisticated decoders. On the other hand, the very low logical error rates that we are targeting make many samples required, necessitating a decoder that is very fast. In addition, it is crucial to utilize realistic noise models that can capture many of the important effects relevant to hardware implementation.
Circuit-level noise simulation. We simulated these codes under a full circuit-level noise model, often regarded as a good proxy for practical performance. Circuit-level simulation accounts for all major noise sources associated with the actual encoding and syndrome-extraction gate operations: gate errors, reset errors, measurement errors, and the specific structure of the syndrome-extraction circuit itself. This is the gold standard for evaluating how a code will actually perform under realistic conditions, because it captures noise correlations and fault paths that simpler models miss.
Our simulations use a physical error rate of p = 0.1%, applied at the circuit level — the widely used convention corresponding to roughly 99.9% physical gate fidelity. Neutral atoms are rapidly approaching this threshold, and QuEra expects to announce progress against this based on experimental demonstrations in the near future.
A hierarchical decoder balancing speed and accuracy. Estimating logical fidelity also requires a decoder, and there is often a challenging trade-off between speed and accuracy for the decoder. Due to this challenge, many papers perform simulations at higher error rates, then extrapolate to the target regime. To gain more confidence in our results given the new code family, we instead took a more rigorous path: we ran actual sampled simulation results through a hierarchical decoder designed to have high accuracy and good throughput, directly verifying the promising performance of our code in relevant regimes.
The decoder cascades through three levels. A fast belief-propagation (BP) pass handles most shots. A relay-BP pass handles cases where standard BP does not converge. An integer-programming decoder handles the remainder. The design hinges on a clean empirical observation: almost all BP and relay-BP failures manifest as non-convergence rather than converging to the wrong result, providing a clear trigger for each escalation. The result is high decoding accuracy at near-BP throughput — fast enough to decode hundreds of millions of samples. We anticipate that with future improvements, the decoding strategy may also be compatible with hardware acceleration for eventual real-time use.
Running sampled simulation data through an actual decoder is a more rigorous and accurate way to estimate the performance of a logical system than extrapolation. The per-logical-per-round error rates we report — approaching the Teraquop regime — are the direct output of this process.
Neutral Atoms: The Common Thread in QEC Advancement
The past two years have been remarkably productive for quantum error correction research. Across the field, teams have advanced code construction, memory simulation, logical operations, and decoding — pushing fault-tolerant quantum computing closer to practical reality than it has ever been.
Many of these significant QEC advances have been built on neutral-atom hardware or designed around neutral-atom capabilities. In 2024, researchers from QuEra co-founder Mikhail Lukin’s Harvard lab, together with collaborators from QuEra, MIT, and UMD/NIST, published a demonstration of a logical quantum processor on reconfigurable atom arrays. Later, constant-overhead fault tolerance using atom transport, below-threshold logical qubits, magic-state distillation, transversal algorithmic fault tolerance reducing runtime overhead by orders of magnitude, and hypergraph product codes mapped to realistic neutral-atom connectivity were all proposed or demonstrated on neutral atoms. And now, ultra-high-rate codes have been co-designed for parallel atom movement.
This is not a coincidence. Neutral-atom platforms offer a combination of properties that align with what QEC algorithms demand: identical qubits by nature, flexible and reconfigurable connectivity, highly parallel operations, and long coherence times relative to gate and transport speeds. These properties make neutral atoms attractive for a wide range of QEC approaches — not just one code family or one technique.
The breadth of that portfolio is the important point. Fault-tolerant quantum computing will not be built on a single paper or a single code. It will require progress across code construction, logical operations, decoding, magic-state preparation, and system integration. Neutral-atom architectures have shown they can support progress on all of these fronts in a flexible and adaptable way.
Our result is one contribution within that broader momentum — advancing the code construction and memory simulation layers with a new code family whose efficiency and hardware compatibility were not previously available. Significant challenges remain, but the direction is clear, and the hardware that enables it is the hardware QuEra builds.
What Comes Next
The paper closes on three open directions, and we are excited to pursue each of them:
- High-rate logical operations compatible with ultra-high-rate encodings — the computation layer that turns memory into a computer.
- Improvements in decoders for real-time implementations of active quantum computation.
- Further code-hardware co-design — the Kasai code family is one point on a broader Pareto frontier, and we look forward to researching other constructions in the future.
Classical communication did not reach the Shannon limit overnight. It took decades of theory-hardware interplay — better codes motivating better silicon, better silicon enabling better codes. That loop is now compressing on the quantum side. The result we're describing here is one concrete step, and the remaining work is an exciting frontier of future research.
What Does This Mean?
For anyone building a quantum computing strategy, whether in government, enterprise, or the research community, the implication is worth sitting with: the physical scale of a useful quantum computer may be significantly smaller than the field has assumed. This changes timelines, infrastructure planning, and which hardware architectures are the most viable paths to fault tolerance.
References
Kasai, 2026 - https://arxiv.org/pdf/2601.08824