



.webp)
The next major advance in quantum computing is not just building more qubits. It is performing enough reliable logical operations to solve problems that classical computers cannot. The first such milestone is the megaquop regime [John Preskill in ACM Trans. Quantum Comput. (2025)]: one million reliable logical operations on an error-corrected quantum computer. It's the regime where quantum simulation of materials, quantum chemistry, and non-equilibrium dynamics moves out of reach for classical methods. The quantum community has been working to reach this computational regime, and neutral atom quantum computers are quickly approaching this target.
Today, we're publishing in PRX Quantum a co-designed architecture, led by QuEra Computing and Los Alamos National Laboratory , that brings that point closer. Based on previous STAR architecture research, we call our neutral atom optimized approach transversal STAR. It delivers orders-of-magnitude savings in space-time cost relative to previously published approaches, putting useful megaquop-scale quantum simulation within reach significantly sooner than many have expected.
Read the paper: Transversal architecture for megaquop-scale quantum simulation with neutral atoms in PRX Quantum
Live webinar: Join the team behind transversal STAR architecture on July 1 at 4:00 PM ET / 1:00 PM PT for a walkthrough and Q&A. Register here.
The MegaQuop Era is Approaching
Over the last few years, quantum error correction has taken center stage. The field is no longer defined by isolated demonstrations of control, coherence, or small algorithmic experiments. Quantum error correction has become a reality on hardware. Logical qubits, repeated syndrome extraction, and early logical gates have all been probed on quantum systems. This progress has brought the community within view of an early fault-tolerant era, the megaquop regime, where quantum computers begin to perform computations that are genuinely out of reach for classical methods.
The size of the quantum computer needed to reach the megaquop scale is driven primarily by quantum error correction overhead. The question for quantum simulation in particular is whether we can implement a million logical operations in a way that reflects the physics of the problem rather than being consumed by overhead. This is the question our research takes on and addresses.
Recent results on ultra-high-rate qLDPC codes, including QuEra's neutral-atom-adapted construction [arXiv:2604.16209], suggest that the memory side of fault tolerance is improving rapidly. These results are complementary: ultra-high-rate codes address how efficiently a machine can hold logical information, strengthening the long-term path toward extremely dense logical memory for large-scale quantum algorithms; transversal STAR targets the challenge of how efficiently we can operate on the encoded logical information in the near term showing that structured megaquop-scale quantum simulation can be very efficient.
Where the Cost of Universal Computation Currently Lives
In standard fault-tolerant architectures, Clifford operations are comparatively cheap, while non-Clifford operations rely on special resource states (magic states), that must be prepared, cultivated, and consumed throughout the circuit. Generating those states is itself a substantial overhead: the current state-of-the-art cultivation algorithm carries 10–50× overhead over the cheapest transversal Clifford gates [arXiv:2409.17595, arXiv:2509.05212].
For simulation workloads, there is often a second penalty layered on top. The natural structure of Hamiltonian simulations is typically not a sparse collection of large non-Clifford magic operations (such as T or CCZ gates), but a dense collection of small-angle rotations stemming from discretized Hamiltonian evolution with short timesteps ("Trotterization").
These small angles are natural from the physics point of view. From the fault-tolerant point of view, when a target rotation is not directly available it has to be synthesized from a discrete gate set to target accuracy 𝜖, with non-Clifford cost scaling roughly as 𝑁𝑠𝑦𝑛~3log2 1/𝜖 in the standard ancilla-free synthesis picture [arXiv:1403.2975]. In the early fault-tolerant regime, with typical simulation angles in the 10⁻²–10⁻³ range with comparable accuracies, the synthesis penalty can be of order 10–50×. The two costs compound:
total cost for small-angle magic = (magic generation) × (angle synthesis)
That product is what currently sits between us and practical megaquop simulation. Anywhere we can shrink either factor, megaquop comes closer.
STAR: Removing the Synthesis Factor
The Space-Time Efficient Analog Rotation (STAR) architecture, originally proposed in [PRXQ 5, 010337 (2024); PRX 15, 021057 (2025)], aims to reduce the compounding overhead. STAR uses the fact that megaquop simulation requires limited gate precision and removes the synthesis cost through a direct scheme for obtaining small-angle logical rotations [arXiv:2303.17380]. Clifford gates are still performed with fault-tolerance with fidelity matching the achievable magic state fidelity. The architecture is not attempting to provide arbitrary universal quantum computation — it cannot tackle arbitrary quantum circuits or go beyond-megaquop error rates — but it aims to be the cheapest route to a class of discretized quantum simulation applications.
That distinction matters. Quantum simulation is not a generic workload with random circuit structure. It comes with locality, repeated patterns, and often large numbers of small-angle rotations. STAR takes advantage of that structure instead of flattening it into a generic non-Clifford resource problem. In practical terms, it removes the synthesis penalty from the precise part of the circuit where simulation spends most of its time.
How STAR Works
The most important technical feature of STAR is the way logical small-angle error scales with angle size. In the regime relevant for simulation, the logical error of an injected rotation behaves approximately as 𝑝𝐿(𝜃)≈ 𝑝ph𝜃. This is exactly the bias one wants for quantum simulation. At hardware-realistic physical error rates of 𝑝ph~10⁻³ and typical simulation angles, the logical error rate in the megaquop regime is achievable.
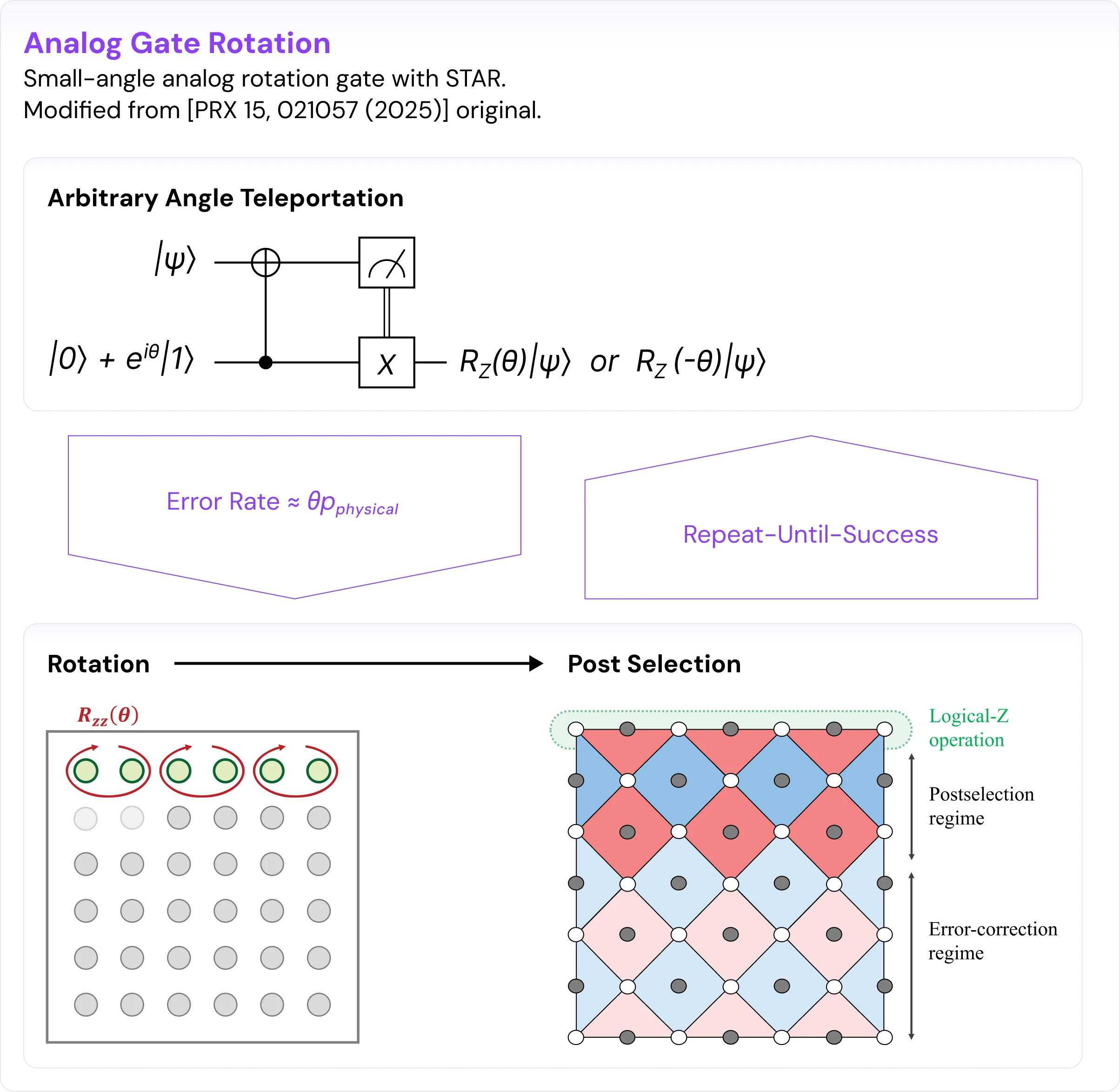
At the heart of STAR is a practical way to implement small-angle logical rotations without resorting to synthesis. The idea is to directly prepare a logical magic state of the form |θ⟩L = RZ,L(θ) |+⟩L and then use teleportation to apply that rotation to the data. This is achieved through a transversal multi-rotation protocol, shown for the surface code in Fig. 1.
One begins by preparing a logical |+⟩L state, typically by initializing physical qubits and performing 1–2 syndrome rounds (logical clock cycles) followed by postselection to encode a logical state with sufficient baseline fidelity. A chosen pattern of physical Z rotations is then applied across qubits that collectively support the logical operator ZL (in the surface code, one row of qubits). The combined action of these rotations approximates the desired logical rotation with the addition of multiple unwanted rotations that also trigger stabilizers of the code. Another 1–2 rounds of syndrome readout follow, allowing one to postselect out the undesired rotation pieces. The protocol is not fault tolerant — its fidelity does not increase with code distance — because physical gate errors during syndrome extraction, with probability pph, can cause a misdetection of undesired rotations of size 𝜃, resulting in a logical error rate proportional to pph.
In effect, the protocol builds the logical rotation out of many small physical rotations applied in parallel, using several rounds of syndrome extraction to postselect errors. The resulting logical state, prepared in the offline injection factory qubits, is then consumed on algorithmic qubits through a quantum teleportation circuit. Because the teleportation stochastically teleports angles 𝜃 and -𝜃 with 50% chance, it is implemented in a repeat-until-success fashion, with an average of two attempts. The key point is that the entire process operates at the same architectural scale as the rest of the computation: it is parallel, compatible with transversal operations, and avoids the need for costly synthesis. This is what allows STAR to deliver small-angle rotations at a cost that is both low and well-matched to quantum simulation workloads.
The Fixed-Connectivity Limit
The original STAR proposals captured the small-angle advantage, but they were framed in a fixed-connectivity setting. That matters because reducing the cost of analog rotations is only half of the problem. If the surrounding logical infrastructure remains slow and layout-heavy, much of the advantage is lost.
In a fixed-connectivity surface-code architecture, logical Cliffords are typically realized through lattice surgery. That means ~d syndrome rounds per Clifford gate, logical ancilla structure for routing operations, and significant logical area spent moving information rather than processing it. The result is a Clifford–magic mismatch: the analog rotation layer is now relatively cheap, but the Clifford layer (including the Cliffords needed to teleport prepared magic) introduces ~10× time and ~2× space overhead for typical megaquop-scale computations over what is theoretically possible.
Neutral Atoms Close the Gap
Flexible, reconfigurable connectivity provides the path to lowering STAR's Clifford and routing overhead. Neutral-atom systems provide exactly that hardware model. By shuttling atoms, interactions no longer have to respect a fixed coupling graph — the logical layout can be organized around the structure of the problem instead of around routing constraints. Combined with large-scale parallelism, this leads naturally to our transversal STAR work [arXiv:2509.18294].
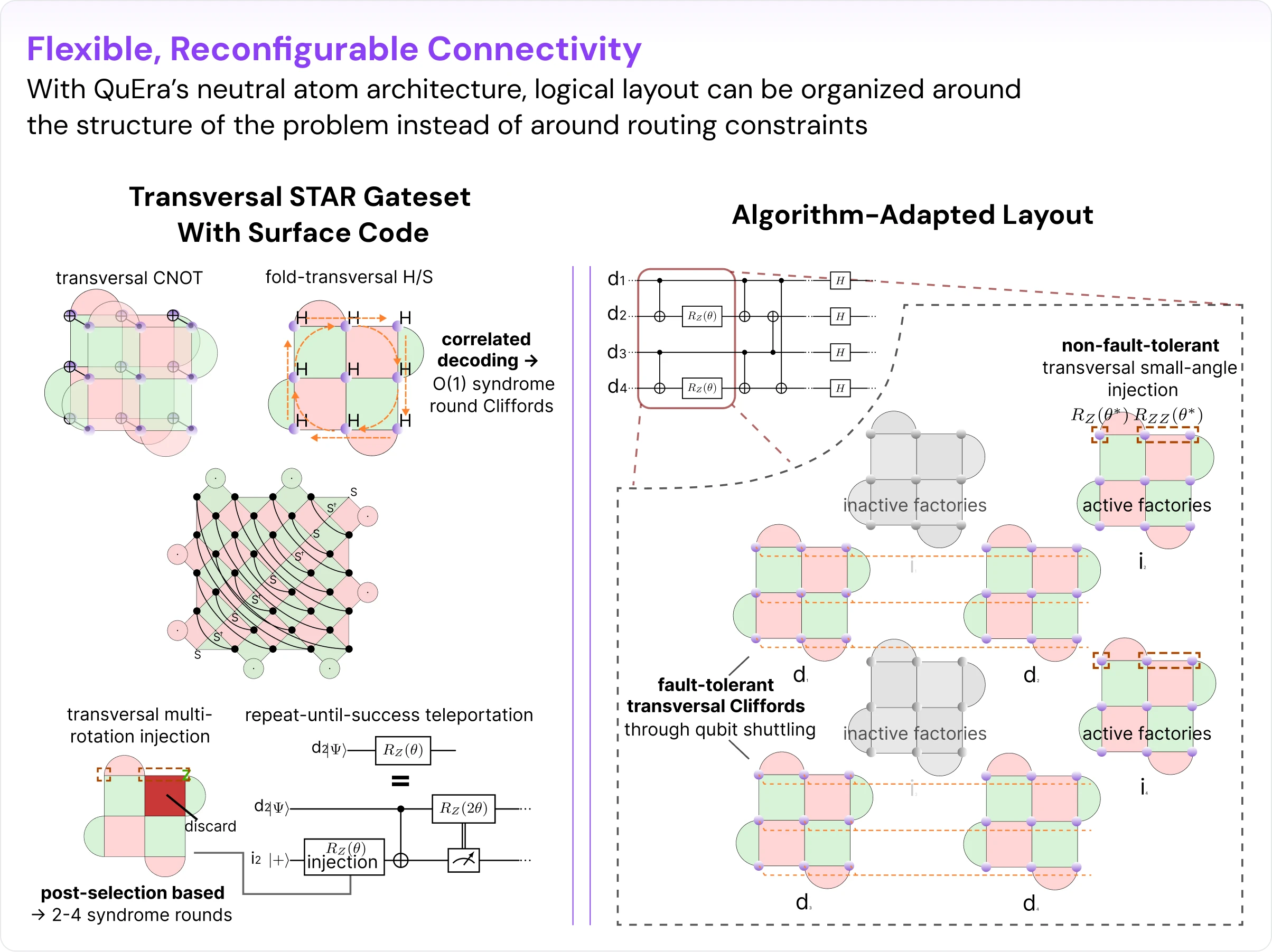
In transversal STAR, transversal and fold-transversal logical Clifford gates are combined with small-angle injection factories in a layout that contains data qubits and factory qubits, but no separate routing patches (Fig. 2). The time cost improves further. As a recent advance led by QuEra and Harvard [Nature 646, 303 (2025)] shows: transversal gates enabled by reconfigurable connectivity can be followed by just ~1 syndrome round rather than the usual ~d cost associated with lattice-surgery logic at code distance d. That removes the speed mismatch between the Cliffords and the analog-rotation magic. What emerges is not just "STAR on a different platform," but a more balanced architecture: no routing overhead, much faster logical gadgets, layout adapted to the simulation problem at hand, and the ability to push parallelism much harder.
Where Transversal STAR Becomes Useful
What simulation scale can we access with transversal STAR, and at what cost? The small-angle magic fidelity gives us the answer. Given the linear relation between logical error rate and angle, the logical angle applicable in a circuit is proportional to the inverse physical error rate, θ𝑇 ≈ 1/𝑝ph ≈ 1000. For a typical local Hamiltonian, the total rotation angle accumulates across all sites (Nq) and over time (T) with θ𝑇≈𝑁𝑞𝑇.
The total simulation volume — the product of the number of logical qubits and the characteristic evolution time (in units of inverse Hamiltonian coupling) — can reach ~1000. For comparison, the fidelities of current NISQ devices limit a well-controlled experiment to a simulation volume of 1–10. Typical fault-tolerant architectures relying on discrete magic would require 10⁶–10⁷ T-gates to perform such calculations.
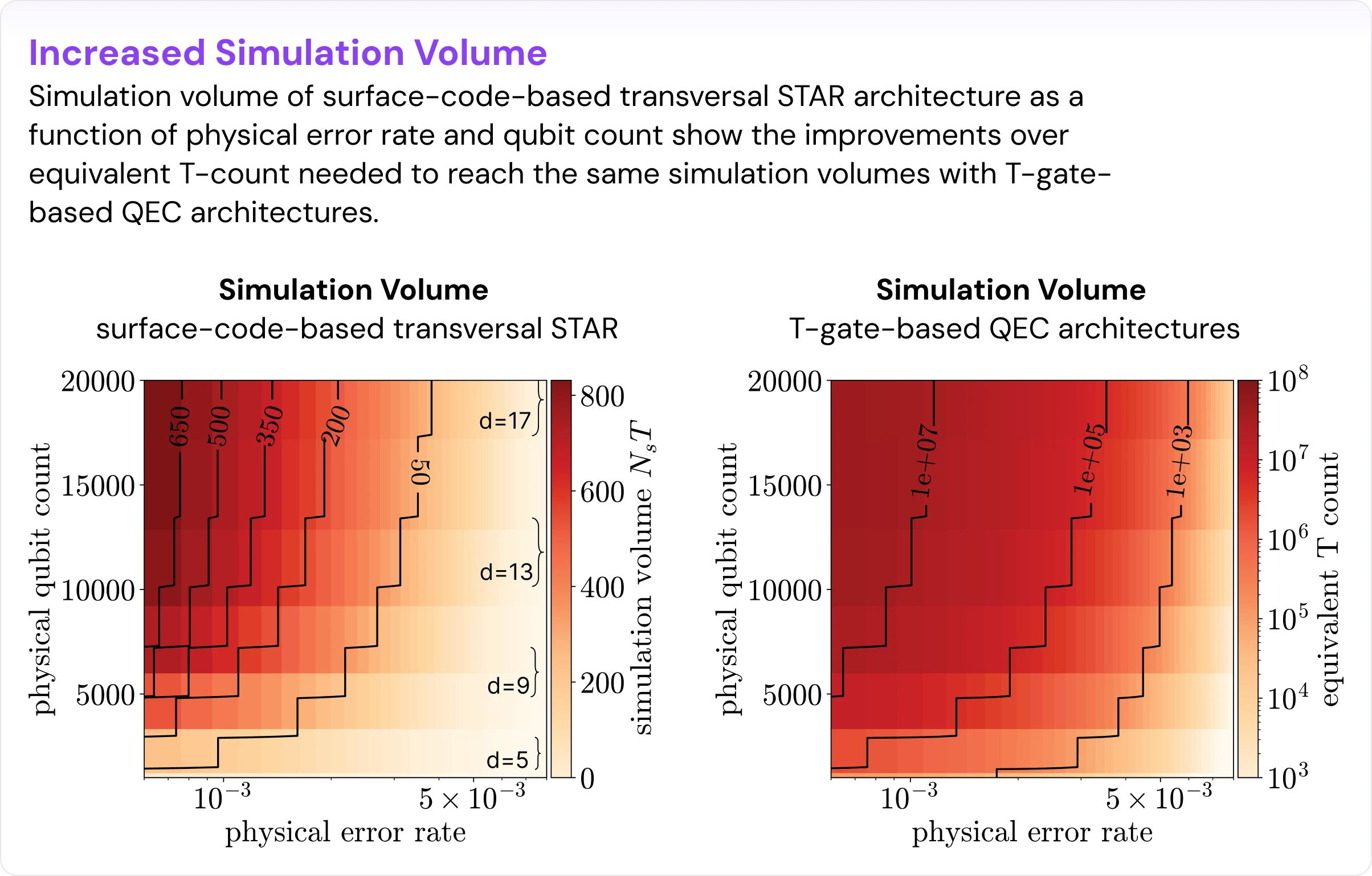
Because the small-angle injection layer remains only partially fault-tolerant, there is a natural operating point beyond which increasing code distance is no longer beneficial. That is part of the design logic, not a flaw. In our recent work [arXiv:2509.18294], detailed simulations with a hardware-inspired noise model at 𝑝ph≈10−3 show that the optimal point for surface-code-based transversal STAR is around d = 9. Both small-angle (θ≈10−3) magic and Cliffords are in the megaquop regime. Quantum simulation with about 100 logical qubits is thus possible with 10,000–15,000 physical qubits (Fig. 3).
Fewer Qubits: High-Rate Codes
Even after those gains, the possibilities enabled by neutral-atom hardware are not exhausted. Nothing in the working principles of STAR is limited to the surface code — small-angle rotation works similarly by piecewise-rotating a logical representative in any stabilizer code. And while the surface code is familiar, robust, and operationally attractive, it remains costly in physical qubits per logical qubit: at code distance 9, 81 physical qubits encode just a single logical one.
In contrast, high-rate quantum low-density parity-check (qLDPC) codes can encode a constant fraction of logical qubits per physical qubit, with encoding rates of 10–20 physical qubits per logical being common [Nature 627, 778 (2024); Nat. Phys. 20, 1084 (2024); arXiv:2510.06159]. Recent ultra-high-rate results suggest that even denser logical memories — up to 2 physical qubits per single logical while achieving teraquop error rates [arXiv:2604.16209] — may be achievable in neutral-atom-compatible settings. The trick that enables such a massive memory footprint reduction is the increased connectivity beyond the nearest-neighbor two-dimensional lattice of the surface code — a perfect match for neutral-atom hardware. These codes have also seen a surge of recent breakthroughs, with new constructions demonstrating both strong error-correcting performance and increasingly practical decoding strategies. What was once largely a theoretical curiosity is becoming a prime candidate for near-term fault-tolerant architectures.
qLDPC codes do come with their own design considerations. Their natural transversal gates are often limited and too global for an arbitrary algorithm, with useful gatesets typically requiring lattice surgery — slow, with extra ancillas eroding some of the space gain. Efficient generation and use of magic also lag behind the surface code, despite recent progress [arXiv:2508.10714]. The magic question is largely resolved for megaquop simulation by STAR's small-angle approach. That naturally raises the next question: can transversal STAR be extended to higher-rate codes without losing the operational simplicity that makes it useful in the first place?
Co-Design: qLDPC-Based Transversal STAR for Structured Simulation
The answer is to lean into structure rather than generality. For local Hamiltonians living on a lattice — relevant for a wide class of materials science and quantum simulation problems — the simulation can be organized through plaquettization [arXiv:2510.06159]. The lattice is decomposed into repeating plaquettes, and the circuit becomes a sequence of parallel intra-plaquette and inter-plaquette operations. Once the computation is organized that way, the code layout can mirror the lattice itself, with the rule that each plaquette contains logical qubits from distinct code patches. Logical blocks are thus distributed congruently with the connectivity of the simulated lattice, with the logical layouts inheriting the geometry of the Hamiltonian.
The second ingredient is symmetry. While the plaquettized logical layout makes intra-plaquette operations simple — entangling gates can be done through global (parallel) transversal CNOTs between logical patches — the inter-plaquette operations are misaligned upon direct transversal CNOT implementation (see Fig. 4). To support parallel inter-plaquette CNOT layers, the code should admit shift (cyclic) automorphisms that act like lattice translations on the logical structure. In addition, to support the needed global single-qubit Cliffords (H and S gates), it is highly advantageous to have an appropriate ZX duality or self-duality. These are not abstract coding-theory niceties: together, parallel transversal CNOTs, shift automorphisms, and ZX duality enable an efficient parallel and transversal gateset that makes the high-rate code usable for the restricted but important class of discretized quantum simulation on a lattice.
Are there good codes that fulfill this symmetry wish list?
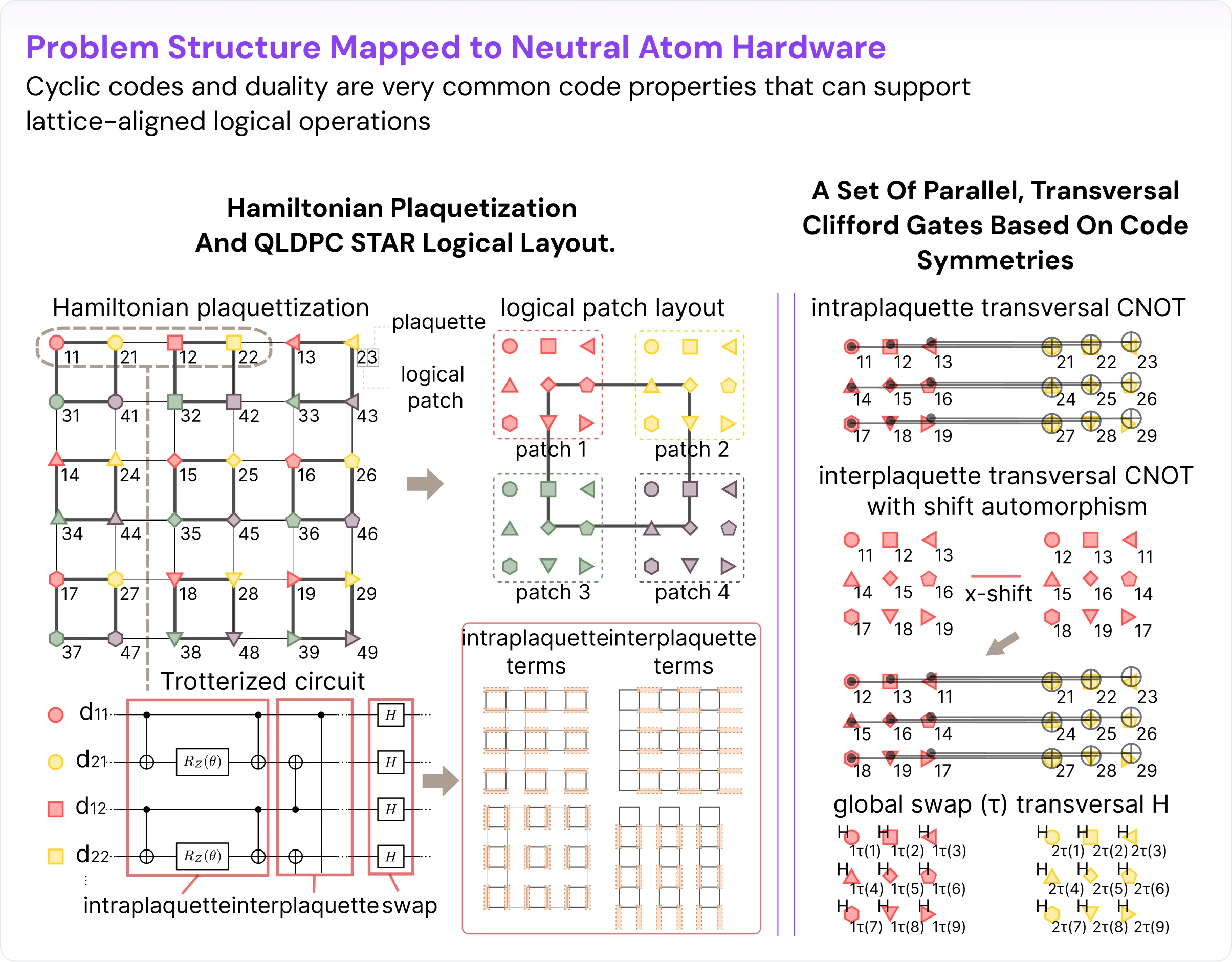
The answer is yes — cyclic codes and duality are very common code properties. One route is hypergraph product codes built from classical cyclic codes, which inherit the translation-like symmetries needed for lattice-aligned logical operations. A representative example is a self-dual hypergraph product code derived from the classical simplex code, with 450 physical qubits encoding 32 logical at code distance 8 [arXiv:2511.09683]. Among the most promising candidates, however, are self-dual bivariate-bicycle (BB) codes [arXiv:2510.06159]. In addition to the right symmetries, these codes have logical operator representatives supported on disjoint subsets of physical qubits, making STAR injection completely parallel. A recent construction [arXiv:2510.06159] produced such a code encoding 6 logical qubits into 66 physical qubits at distance 8. Importantly, both hypergraph product codes and bivariate-bicycle codes are readily congruent with the hardware move parallelism of neutral atoms, with the underlying symmetries largely responsible.
Our fully parallel and transversal qLDPC STAR construction is thus complete. Note that arbitrary logical computation on qLDPC codes has not suddenly become straightforward, but for structured quantum simulation, the right code symmetries provide exactly the restricted but efficient logical gateset the application needs.
A Faster Route to Useful Quantum Simulation
With both the surface-code and high-rate constructions in view, the natural question is what all of this adds up to. The savings are not incremental. They are architectural.
At the surface-code level, transversal STAR brings the cost of a representative megaquop-scale simulation step (example: Ising model on an 8×8 lattice) down to about ~60 clock cycles with roughly 15,500 physical qubits. In the high-rate qLDPC version, the clock-cycle cost remains in the same range — about 60–130 clock cycles — while the physical footprint drops to about 3,000 qubits (or 1,500 qubits per single calculation).
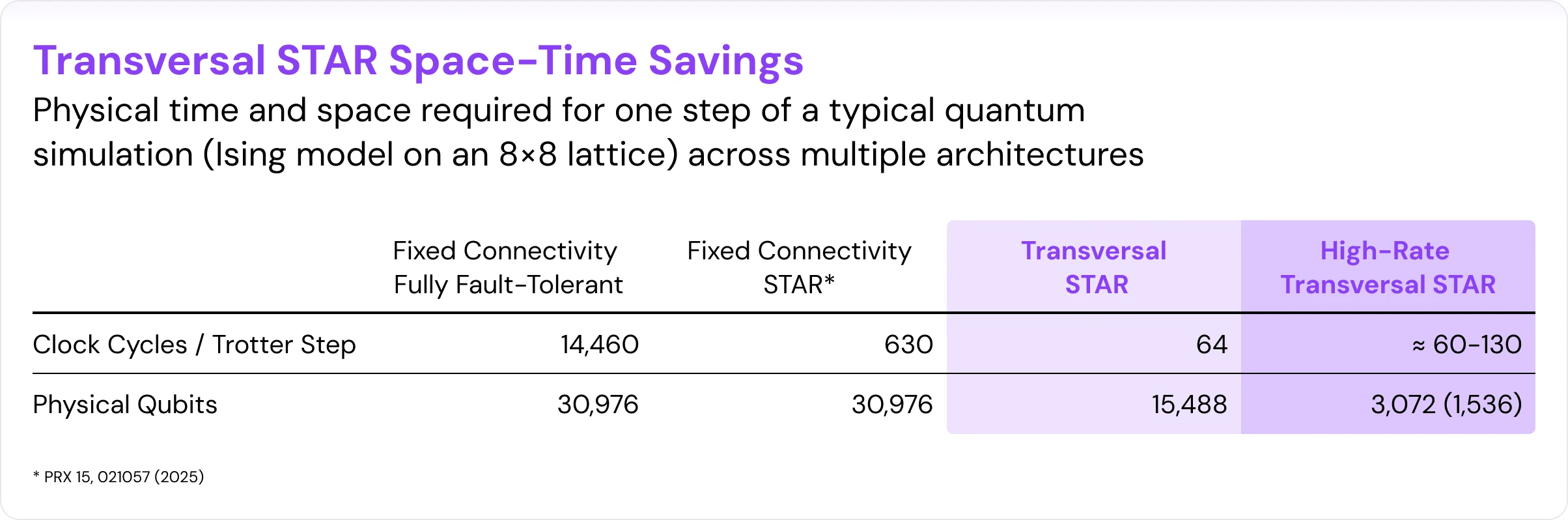
This translates into a striking advantage over more conventional approaches:
- Against fixed-connectivity fully fault-tolerant architectures, transversal STAR with surface code is about 250× faster and uses roughly 2× fewer qubits.
- With high-rate qLDPC codes, most of that time advantage is retained while the qubit count is reduced by another ~5×.
- Against earlier fixed-connectivity STAR proposals, the neutral-atom transversal version is about 10× faster and 2× smaller with surface code, with the qLDPC version reaching roughly 10–20× space savings.
Transversal STAR in the Broader QEC Landscape
Transversal STAR is one piece of a quickly evolving QEC picture. The field is moving on several fronts at once: ultra-high-encoding rates [arXiv:2604.16209], parallel addressable operations [arXiv:2510.08523], more efficient magic state generation [arXiv:2510.06159], performant and fast decoders [arXiv:2604.08358], to name a few. Together, these developments are reshaping what fault tolerance on neutral-atom hardware — and more broadly — can look like.
What makes transversal STAR distinctive in that picture is its target and its balance. It is aimed squarely at structured quantum simulation in the early fault-tolerant regime, where the central question is not only how to protect logical information but how to do useful computation without spending most of the budget on overhead. By combining cheap small-angle logical rotations with fast transversal Cliffords and flexible neutral-atom connectivity, it offers an unusually favorable combination of operational simplicity and space-time efficiency.
This work also extends the QuEra fault-tolerant momentum from 2025 — including four Nature papers published in collaboration with, and in several cases led by, QuEra's academic partners at Harvard and MIT, on continuous operation of multi-thousand-atom arrays [Nature 646, 1075(2025)], integrated fault-tolerant architectures with up to 96 logical qubits [Nature 649, 39 (2026)], the first logical magic state distillation [Nature 645, 620 (2025)], and transversal fault tolerance that reduced runtime overhead by 10–100× [Nature 646, 303 (2025)] — from hardware advances into architectural ones. QuEra continues to focus all R&D efforts on delivering large-scale, universally fault-tolerant quantum systems. Transversal STAR is a near-term path to beyond–classical simulation built on the same neutral-atom capabilities — reconfigurable connectivity, parallelism, transversal gates — that underpin that long-term roadmap.
Early fault-tolerant quantum advantage will not come from error correction alone, or from hardware scaling alone. It will come from architectures that make the hardware, the code, and the application reinforce one another. In that emerging landscape, transversal STAR stands out as a particularly promising route to efficient megaquop-scale quantum simulation on neutral atoms.
Read the paper: Transversal architecture for megaquop-scale quantum simulation with neutral atoms, PRX Quantum.
Live webinar: July 1 at 4:00 PM ET / 1:00 PM PT — a walkthrough of the transversal STAR architecture and live Q&A with the team. Register here.





