


.webp)
At a Glance: Merck, Amgen, Deloitte, and QuEra Computing recently collaborated on a proof-of-concept quantum case study, leveraging quantum reservoir computing (QRC) to address a common pain point in pharmaceutical R&D—making reliable predictions from small datasets, such as those found in early-stage clinical trials or rare-disease cohorts.
Background: Why Small Data Matters in Drug Development
Clinical trials—especially in oncology, precision medicine, or treatments for rare diseases—often suffer from limited sample sizes. Traditional machine learning techniques frequently overfit or exhibit unstable predictions when trained on such small datasets, undermining their utility in real-world deployment.
Seeking a more robust alternative, the consortium explored Quantum Reservoir Computing (QRC), a hybrid quantum-classical framework where a fixed quantum system (a “reservoir”) transforms inputs into enriched representations without requiring training of the quantum component itself—a potent approach when data is scarce.
Method: How QRC Was Implemented
- Data Preparation and Sub-sampling
Deloitte orchestrated a data pipeline built to simulate small-data scenarios. Starting from a larger molecular dataset, the team created subsets of varying sizes (e.g., 100, 200, 800 samples) using clustering to preserve the underlying data distribution. - Quantum Embeddings with QuEra’s Neutral-Atom QPU
- Molecular features were encoded into control parameters—like atomic detunings or atom arrangements—into QuEra’s neutral-atom quantum system.
- As the system evolved under Rydberg interactions, measurements produced high-dimensional “quantum embeddings.”
- Crucially, only the classical readout layer (e.g., random forest) was trained, simplifying the hybrid workflow and avoiding the pitfalls of quantum gradient training.
- Classical Comparisons
The pipeline compared three configurations:- Classical models on raw features.
- Classical models on kernel-transformed embeddings (e.g., Gaussian RBF + random forest).
- Quantum reservoir embeddings, followed by classical modeling.
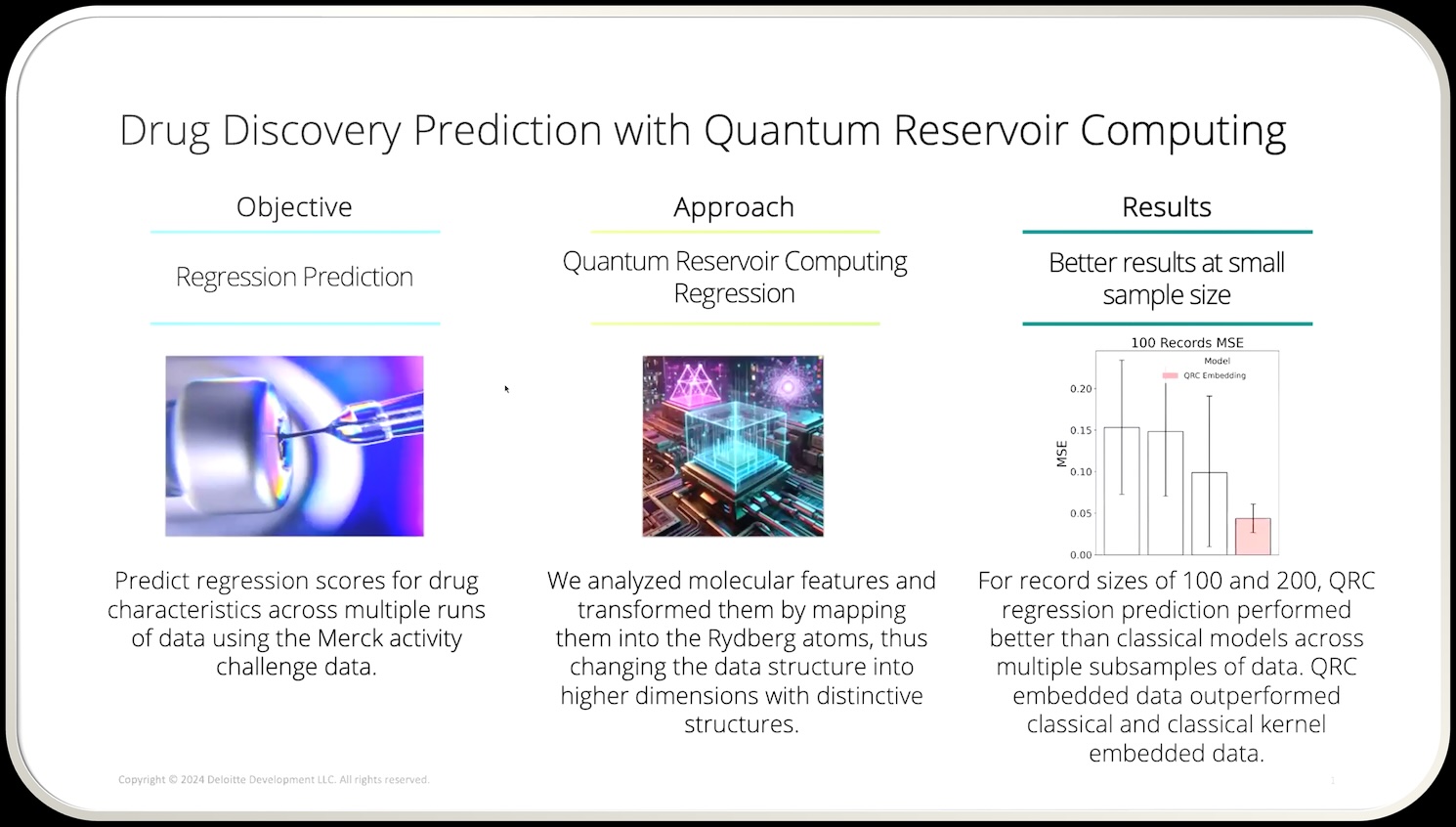
Results: Doing More with Less
- Small Data (100–200 samples):
QRC outperformed both raw-feature and classical embedding approaches, delivering higher predictive accuracy and significantly lower prediction variability. - Larger Data (≥800 samples):
The advantage of QRC diminished, with classical methods catching up—highlighting QRC’s core strength: superior performance in low-data regimes. - Nonlinearity Matters:
Embeddings that leveraged richer (two-body) quantum interactions yielded stronger performance gains—emphasizing the value of exploiting quantum system nonlinearity. - Interpretable Embeddings:
Visual clustering via UMAP revealed that quantum embeddings structured data more distinctly across key variables—offering clearer separations than classical methods.
What’s Next: Looking Beyond Molecules
While this study focused on molecular property prediction, its implications span much further:
- Clinical Time-Series & Biomarkers:
Domains like voice-based neurology markers or ECG/EKG time-series, where data is inherently limited and highly nonlinear, could benefit from QRC’s robust embeddings. - Missing Data Imputation:
The goal of rebuilding partial records from EHRs or clinical data could be better served by models that capture complex interdependencies effectively—a strength of QRC. - Scaling Toward Quantum Advantage:
Current experiments used tens of qubits—potentially simulatable classically. As neutral-atom hardware scales into the hundreds, QRC may enter regimes where classical reconstruction becomes infeasible, opening the door to true quantum advantage.
Why This Matters for HPC-Enabled R&D
For HPC managers and facility planners in pharma or life sciences:
- Testable Hybrid Models: QRC demonstrates meaningful value today—no fault-tolerant quantum hardware is required. It integrates into existing classical pipelines with minimal overhead and tangible gains in small-data scenarios.
- Operational Simplicity: Encoding into quantum embeddings avoids complex quantum training, easing adoption and reducing algorithmic fragility—a pragmatic fit for HPC co-design pilots.
- Forward-Looking Scale: Scaling hardware naturally boosts QRC’s utility in more complex datasets—ideal for future-ready centers anticipating deeper quantum-classical synergies.
Summary Table
This case study is a model for how quantum reservoir computing can start showing value in HPC-enabled life science workflows today, with strategic scaling toward deeper quantum-classical integration tomorrow.
.webp)
.jpg)



